Every CTO knows this moment. Your engineering team has grown from 50 to 500 people. What used to take two weeks now takes two months. Features that once shipped smoothly now get stuck in endless review cycles. Your best developers spend more time in meetings than writing code.
You are not alone. This is the predictable crisis of scale, and it happens to nearly every organization that grows past a certain threshold.
The question is not whether you will face this challenge. The question is whether you will recognize it early enough to do something about it.
The Velocity Paradox
Here is what seems to make no sense: you hire more engineers to move faster, but your organization slows down. You add more process to improve quality, but delivery timelines stretch. You invest in better tools, yet productivity declines.
This is not a failure of your people or your technology. It is a failure to understand what actually drives velocity at scale.
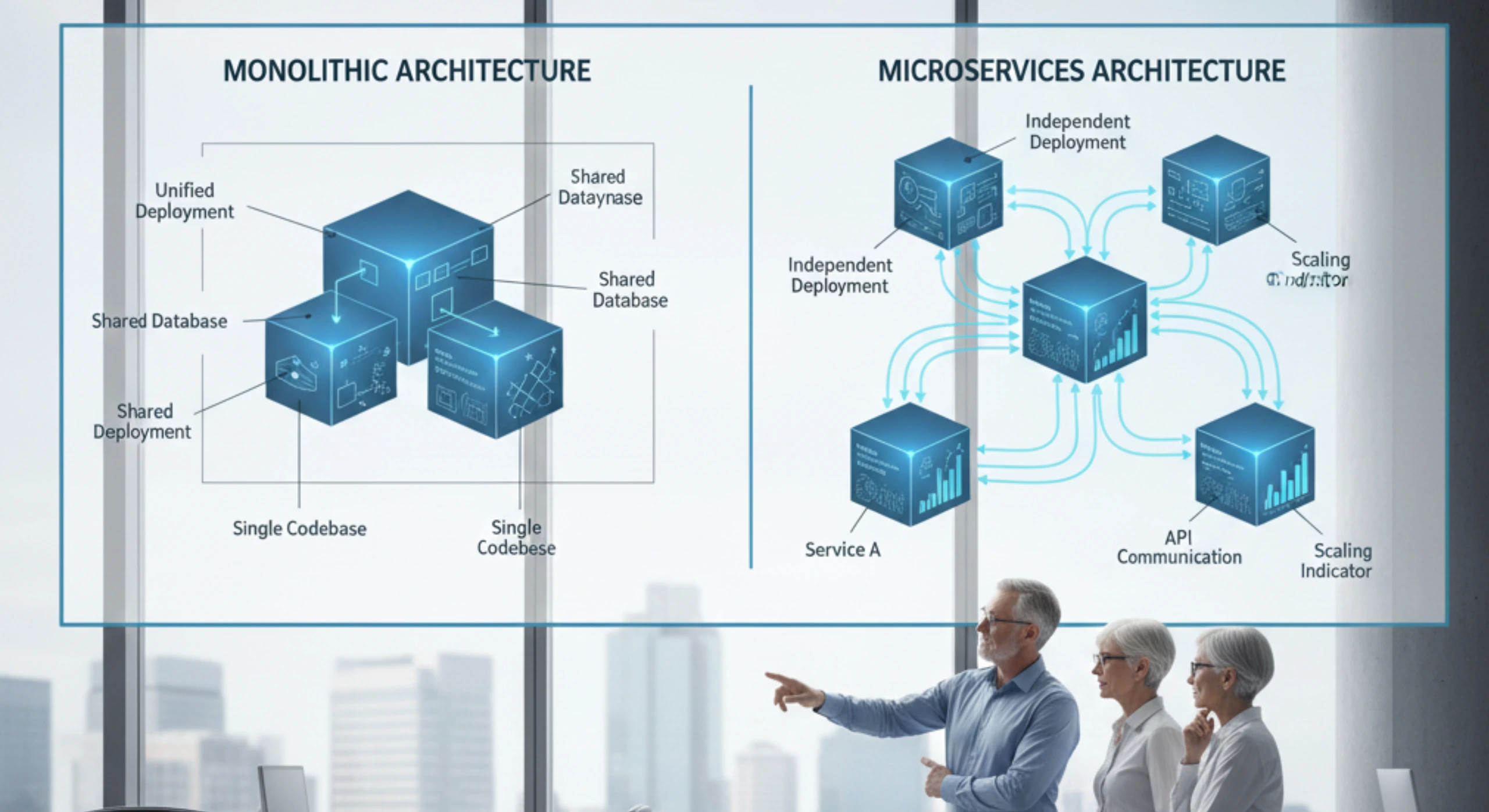
Most executives think the problem is technical. They look at their technology stack, their architecture, their cloud infrastructure. They commission reports on microservices adoption or platform modernization. They hire consultants who recommend the latest frameworks.
But the real problem is organizational. It is about how decisions get made, how ownership gets distributed, how accountability flows through the system.
What Actually Slows Down Large Teams
Let me be direct about what happens in most large engineering organizations.
Too many approvals. Every decision requires sign-off from multiple stakeholders. A simple API change needs approval from security, compliance, architecture review boards, product committees, and three levels of management. What could take one day takes three weeks.
Unclear ownership. No one really owns the end-to-end outcome. Developers own the code. Product managers own the roadmap. DevOps owns deployment. But no single person owns whether the customer actually gets value. So when things go wrong, everyone points at someone else.
Coordination overhead. With 500 engineers, you have 500 different mental models of how the system works. Every feature requires coordination across multiple teams. Every release needs careful choreography. The communication overhead grows exponentially while the actual work grows linearly.
Risk aversion. As organizations grow, they become more conservative. People remember the big outage from two years ago. They remember the security incident. They remember the compliance violation. So they add checkpoints, add reviews, add gates. Each one seems reasonable in isolation. Together, they create paralysis.
Legacy complexity. Your system has grown organically over years. Parts of it are well-designed. Parts of it are held together with duct tape and prayer. Nobody wants to touch the old code because nobody fully understands it. So new features get built around the legacy mess, adding more complexity instead of reducing it.
This is the reality in most large organizations I have seen. In India, where many enterprises still run mission-critical operations on systems built 15 or 20 years ago, this problem is even more acute.
The Cost of Slow Delivery
Executives often underestimate how much slow delivery actually costs.
The obvious cost is time-to-market. Your competitor launches a feature in three months. You take nine months. They capture the market. You play catch-up.
But there are hidden costs that matter more.
Talent loss. Good engineers do not want to work in slow organizations. They join because they want to build things that matter. When they spend six months navigating approvals to ship a simple feature, they leave. You lose your best people and keep the ones who have learned to work the system.
Innovation drain. When everything takes forever, people stop suggesting new ideas. Why propose something bold when you know it will die in committee? The organization becomes reactive instead of proactive. You stop leading your market and start following it.
Compounding delays. Every delayed project creates a cascade effect. The marketing launch gets pushed. The customer commitment gets missed. The board starts asking uncomfortable questions. Leadership attention shifts from strategy to firefighting. More delays follow.
I have seen enterprise programs where the initial timeline was 12 months and the actual delivery took 36 months. The budget overrun was the least of their problems. By the time they launched, the market had moved on.
What Separates Success from Failure
After working with dozens of large-scale programs, I can tell you that success is not about having the smartest architects or the latest technology. It is about getting the fundamentals right.
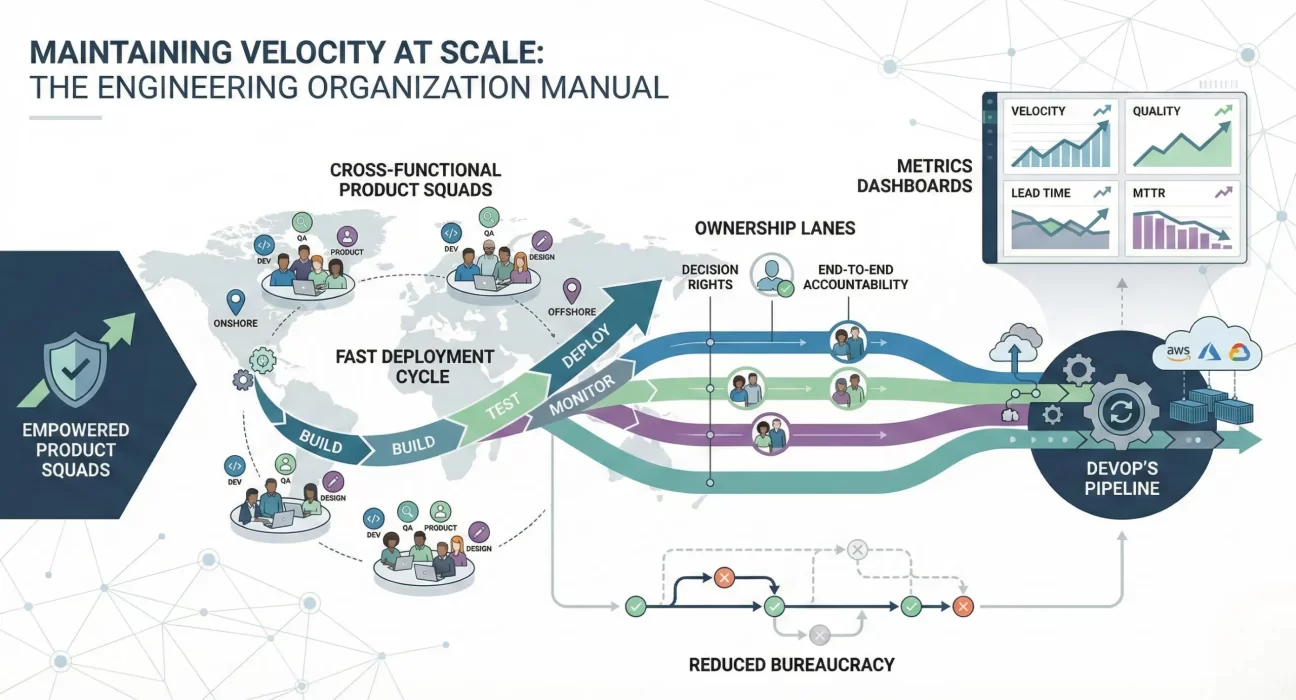
Clear ownership structure. Successful organizations assign end-to-end ownership to small, empowered teams. Not ownership of a component or a service, but ownership of a business outcome. One team owns the entire customer onboarding experience. Another team owns the payment flow. Each team has the authority to make decisions within their scope without endless escalation.
This does not mean chaos. It means intentional autonomy. You set clear boundaries, define interfaces between teams, establish quality standards. Within those constraints, teams move fast.
Decision-making discipline. Fast organizations distinguish between reversible and irreversible decisions. Reversible decisions get made quickly at the lowest possible level. Irreversible decisions get careful review at the right level. The key is not to treat everything as irreversible.
Most organizations do the opposite. They treat every decision as if it might sink the company. So they slow everything down. Meanwhile, the cumulative effect of slow decision-making actually creates more risk than any individual decision ever would.
Delivery cadence. Teams that maintain velocity ship regularly. Not big releases every six months, but small releases every week or two. This forces discipline. It forces you to break work into manageable chunks. It forces you to automate testing and deployment. It forces you to keep quality high because you cannot afford to accumulate technical debt.
When teams ship frequently, they also get faster feedback. They learn what works and what does not. They build better intuition about what customers actually need.
Technical capability. You cannot maintain velocity with poor engineering practices. You need solid testing. You need reliable deployment pipelines. You need good monitoring and observability. You need the ability to roll back quickly when something goes wrong.
But here is the thing: these capabilities matter only if the organizational structure allows you to use them. I have seen organizations with excellent DevOps infrastructure where deployments still take weeks because of approval processes. The technology was not the constraint.
The Leadership Gap
The hardest part of maintaining velocity is not technical. It is leadership.
Most technology leaders in large organizations rose through the ranks by being excellent individual contributors or by managing small teams. The skills that got them there do not necessarily prepare them for leading at scale.
Leading a 500-person engineering organization requires different skills than leading a 50-person team. You cannot review every pull request. You cannot attend every planning meeting. You cannot make every technical decision.
You have to lead through systems, not through individual interventions.
This means setting clear principles and trusting your teams to apply them. It means creating feedback loops that surface problems early. It means building a culture where people feel safe to raise issues and safe to make decisions.
It also means being willing to make hard calls about organizational structure. Sometimes you have to break apart teams that have worked together for years. Sometimes you have to sunset projects that people have invested in. Sometimes you have to move fast even when not everyone agrees.
These decisions are uncomfortable. They create short-term friction. But avoiding them creates long-term paralysis.
Governance Without Bureaucracy
Large organizations need governance. You have regulatory requirements. You have security standards. You have financial controls. You have stakeholder commitments.
The challenge is implementing governance without creating bureaucracy.
Bureaucracy is what happens when you confuse activity with outcomes. You create a review board. The board meets every week. People prepare elaborate presentations. The board asks questions, requests changes, schedules follow-ups. Everyone is busy. Nothing actually improves.
Good governance is different. It focuses on outcomes, not process. It asks: are we delivering value to customers? Are we managing risk appropriately? Are we building for sustainability?
One pattern that works well is to separate architecture decisions from execution decisions. You set architectural principles and standards centrally. Teams execute within those standards autonomously. You review adherence through automated checks and periodic audits, not through approval gates on every change.
Another pattern is to make governance asynchronous wherever possible. Instead of requiring everyone to attend a meeting, publish the proposal, give stakeholders a window to review and comment, then make the decision. If someone has a serious concern, they can raise it. Otherwise, the default is to proceed.
This respects everyone’s time and creates a bias toward action.
The Vendor and Partner Reality
Most large enterprises in India work with multiple vendors and partners. Some build custom solutions. Some provide SaaS platforms. Some offer staff augmentation. Some take on program management.
Managing this ecosystem is one of the hardest parts of maintaining velocity.
The typical pattern is this: you hire a vendor to accelerate delivery. Initially, things move fast. The vendor brings in a large team. They start building features. But over time, integration becomes messy. Quality issues emerge. Knowledge stays with the vendor instead of transferring to your team. When the contract ends or the vendor team changes, you are left with code nobody understands.
This is not necessarily because vendors are incompetent. It is because the engagement model was wrong from the start.
Vendors succeed when they are measured on code delivered or hours billed. You succeed when you deliver value to customers. These incentives do not align naturally. You have to align them intentionally.
The best partner relationships I have seen share a few characteristics. The partner truly understands your business context, not just your technical requirements. They bring experienced people who have solved similar problems before, not just available resources. They focus on building your internal capability, not creating dependency. And they have skin in the game for actual outcomes, not just deliverables.
This is why companies like Ozrit position themselves differently from traditional vendors. Rather than just providing development resources, they take ownership of program execution and delivery maturity. They work alongside your teams to establish the practices and systems that sustain velocity long after the engagement ends.
The distinction matters. A vendor delivers what you asked for. A partner helps you figure out what you actually need.
Legacy Systems and Technical Debt
Every large organization carries technical debt. Systems built ten years ago that still run core business processes. Databases with schemas that made sense once but now constrain everything. Integration layers that have evolved into tangled dependency graphs.
You cannot maintain velocity while ignoring this debt. But you also cannot stop everything to rewrite your entire stack.
The pragmatic approach is selective modernization. You identify the parts of your system that create the most drag on velocity. Maybe it is a deployment process that requires manual steps and takes three days. Maybe it is a shared database that causes constant conflicts between teams. Maybe it is a legacy API that forces every new feature to work around its limitations.
You tackle these bottlenecks systematically. Not through big-bang rewrites, but through incremental improvements. You build a new API alongside the old one and gradually migrate consumers. You extract a service from a monolith and prove it works before extracting the next one. You automate one manual step at a time until the entire process is automated.
This requires discipline. It requires saying no to feature requests so you can invest in infrastructure. It requires explaining to business stakeholders why spending three months on something that has no visible customer impact will actually accelerate the next six months of delivery.
Not every executive understands this tradeoff. The good ones do.
Metrics That Actually Matter
Most organizations measure the wrong things. They track lines of code written, the number of features delivered, or story points completed. These metrics create the appearance of progress without measuring actual value.
If you want to maintain velocity, measure cycle time from idea to production. Measure how long it takes to respond to a customer issue. Measure deployment frequency and deployment success rate. Measure how much time your teams spend on planned work versus unplanned work.
These metrics tell you whether your organization is actually delivering value or just staying busy.
You should also measure leading indicators, not just lagging ones. By the time revenue drops or customer satisfaction declines, the damage is done. But you can see early signals in your engineering metrics. If deployment frequency is declining, velocity will follow. If the ratio of bug fixes to new features is increasing, technical debt is accumulating. If the time to resolve incidents is growing, your systems are becoming more fragile.
Good leaders watch these signals and act before problems become crises.
Building for Sustainability
Velocity is not about moving fast for six months and then burning out. It is about building a sustainable pace that you can maintain for years.
This requires investing in your people. Good engineers do not just appear. You have to develop them. You have to create growth paths. You have to give them challenging problems and support them in solving those problems. You have to build an environment where learning is valued and where it is safe to admit what you do not know.
It also requires protecting your teams from organizational chaos. Every large organization has competing priorities, shifting strategies, and political dynamics. Your job as a leader is to absorb that chaos so your teams can focus on execution. This does not mean shielding them from reality. It means translating business pressures into clear priorities and stable commitments.
When priorities change every week, teams cannot build momentum. When commitments get broken regularly, trust erodes. When leaders say one thing and reward another, culture deteriorates.
Maintaining velocity requires consistency over time.
The Path Forward
If you are leading a large engineering organization that has lost velocity, you probably cannot fix everything at once. Start with one or two high-impact changes.
Maybe you start by simplifying your deployment process. Maybe you give one team genuine end-to-end ownership and see how it works. Maybe you establish a discipline of shipping smaller increments more frequently. Maybe you bring in a partner who has walked this path before and can help you navigate it.
The important thing is to start. The cost of delay compounds. Every month you wait is a month your competitors use to pull ahead.
But also understand that this is a journey, not a project. You do not restore velocity through a three-month transformation program. You restore it through consistent attention to the fundamentals over the years.
You need leaders who understand this. You need partners who understand this. You need patience and persistence.
The good news is that it works. I have seen organizations rebuild their velocity after years of decline. I have seen teams go from deploying once a quarter to deploying multiple times per day. I have seen engineering cultures transform from risk-averse and bureaucratic to bold and entrepreneurial.
It requires getting the basics right: clear ownership, good governance, technical discipline, sustainable pace, and aligned incentives.
The organizations that figure this out do not just move faster. They build better products. They attract better talent. They create more value for customers. They win their markets.
The question is not whether maintaining velocity is possible at scale. The question is whether you are willing to do what it takes.