The engineering team structure you choose in the first month of an enterprise program will either enable success or guarantee failure two years later.
Most executives don’t realize this until it’s too late. They approve a team structure that looks reasonable on paper: a mix of architects, developers, testers, maybe a scrum master or two. The vendor says they’ll scale up as needed. The project plan shows clear phases. Everything seems organized.
Eighteen months in, the program is drowning. The original tech lead left six months ago. Three different teams are building integration layers that don’t talk to each other. Nobody knows who owns the data model. The business is asking for changes that should take days but somehow take months. And the people who actually understand how everything fits together are completely burned out.
This happens because most enterprise programs structure their engineering teams for the project they wish they had, not the one they actually have.
Why Team Structure Matters More Than You Think
In a three-month project with a clear scope, team structure is relatively straightforward. You need some developers, a tech lead, maybe a QA person. The work is limited. The relationships are simple. One team can hold the context.
Enterprise programs are different animals entirely.
They run for years, not months. They touch multiple business domains. They integrate with systems that were built before most of your developers were born. They require compliance with regulations that keep changing. They involve hundreds of people across multiple vendors, geographies, and organizational silos.
In this environment, how you structure your engineering teams determines whether knowledge gets shared or hoarded, whether decisions get made or deferred, whether quality improves or degrades, and whether the system being built is coherent or just a collection of loosely connected modules.
Get the structure wrong and you end up with the classic enterprise program pathologies: duplicated effort, inconsistent patterns, integration nightmares, knowledge silos, and teams that can’t move fast because they’re constantly waiting on other teams.
Get it right and you have teams that can operate with reasonable autonomy, make decisions quickly, deliver consistently, and actually enjoy their work instead of dreading every standup.
The Mistakes We See Repeatedly
Walk into most struggling enterprise programs and you’ll see the same structural mistakes.
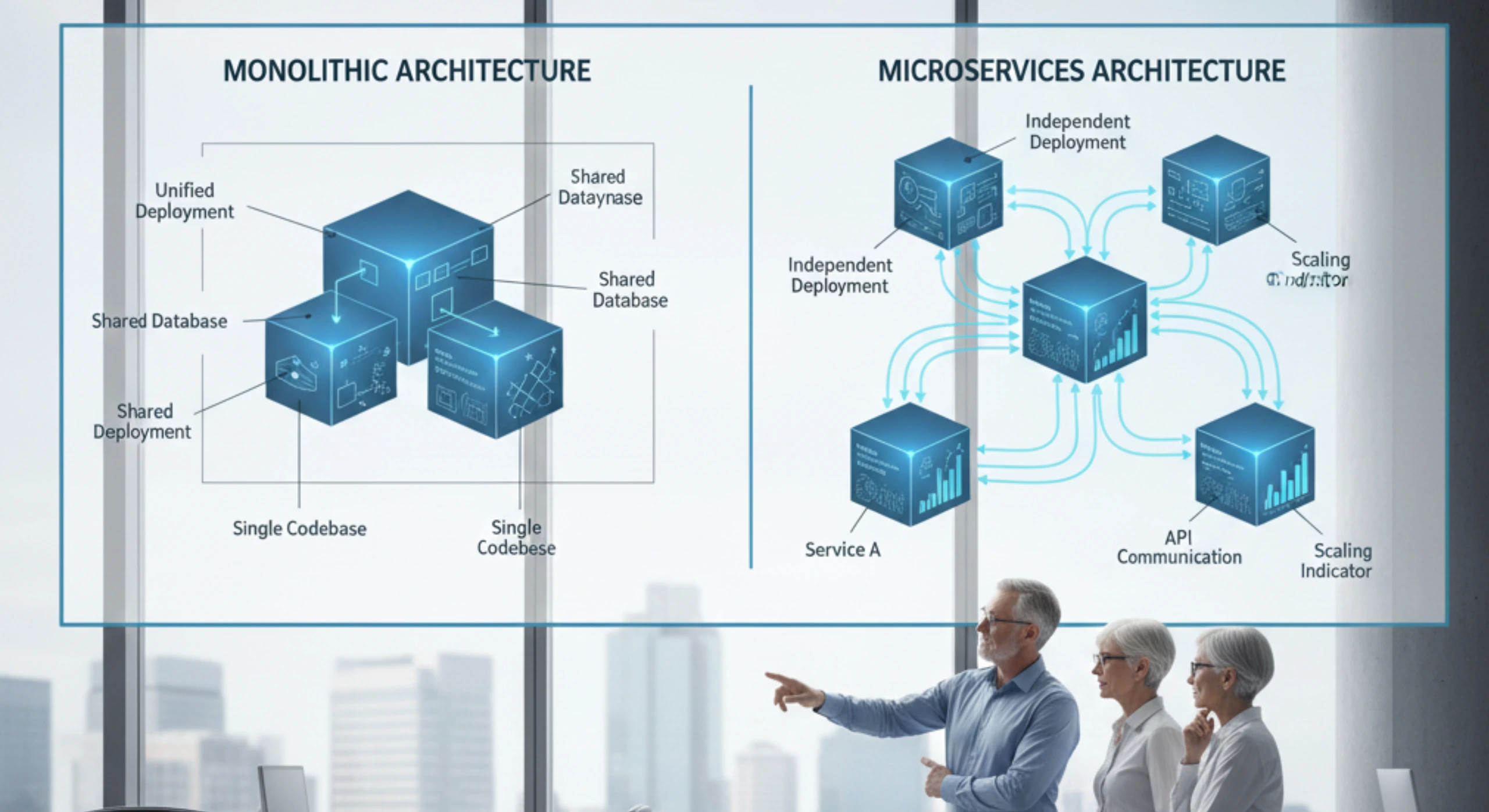
The first is what we call the “resource pool” model. The program treats engineers as interchangeable resources to be allocated wherever there’s work. Need three Java developers? Pull them from the pool. Need two testers? Grab whoever’s available. This feels efficient on a spreadsheet but it’s disastrous in practice. You end up with no team continuity, no ownership, and constant context-switching that destroys productivity.
The second mistake is organizing teams purely around technology layers: a backend team, a frontend team, a database team, an integration team. This creates dependencies at every turn. To deliver even a simple feature, you need coordination across four teams. Every change requires negotiation. Every decision requires a meeting. Velocity collapses.
The third is the outsourcing model where you hand an entire layer or module to a vendor and assume they’ll just deliver it according to specs. The vendor team operates in isolation, often offshore with minimal interaction with the rest of the program. When integration time comes, you discover their understanding of requirements diverged from reality six months ago. Nobody caught it because the teams weren’t actually working together.
The fourth mistake is not planning for continuity. Teams are staffed for the build phase, but when you move into stabilization and then operations, half the people rotate off. The knowledge walks out the door. Six months after go-live, nobody remembers why certain decisions were made or how certain components work.
And finally, there’s the leadership gap. Programs create elaborate team structures but don’t put strong technical leaders in place to hold it all together. You have teams but no one who can see across teams, spot problems early, make binding technical decisions, and maintain architectural coherence.
The Principles That Actually Work
After working with enterprise programs across banking, insurance, manufacturing, and government sectors, we’ve learned that successful team structures share common principles.
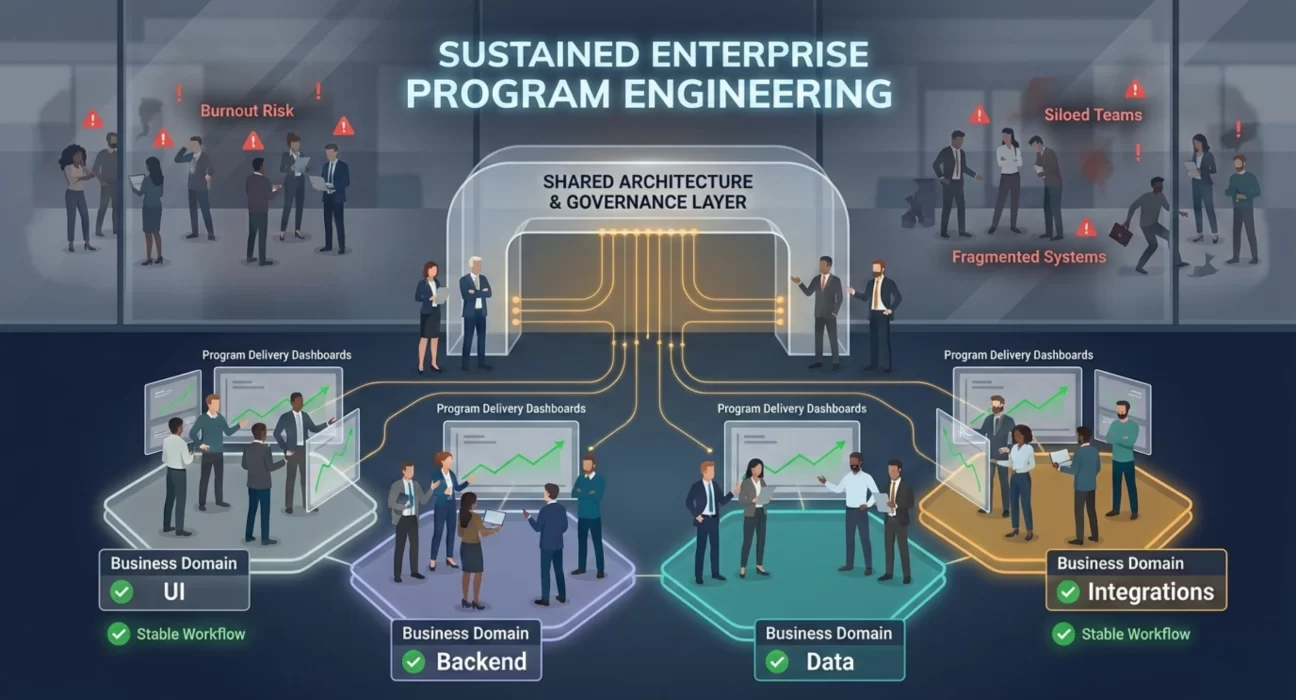
The first principle is ownership over coordination. Teams should own complete capabilities, not just layers. Instead of a frontend team and a backend team, you want a team that owns the customer onboarding capability end to end. They own the API, the business logic, the data, the UI, the integrations everything needed to deliver and evolve that capability. This doesn’t mean they can’t share platforms or reuse components, but it means they can ship features without coordinating handoffs across five other teams.
The second principle is stability over flexibility. In enterprise programs, team continuity is more valuable than the theoretical flexibility of moving people around. Keeping the same group of people working on the same domain for an extended period means they build deep knowledge, they develop working relationships, they improve their processes, and they start moving faster, not slower. The instinct to constantly reorganize teams or rotate people for “exposure” is almost always counterproductive.
The third principle is technical leadership at every level. You need architects who set direction, but you also need strong tech leads embedded in each team who can make day-to-day decisions without escalating everything. These leads need both technical depth and enough organizational maturity to navigate the politics and complexity of enterprise delivery. Finding and keeping these people is one of the highest-leverage investments you can make.
The fourth principle is explicit integration ownership. In any enterprise program, the integration layer, the connections between your new systems and existing core systems is where most of the risk lives. This can’t be an afterthought. You need a dedicated integration team with deep knowledge of your legacy landscape, the authority to define integration patterns, and the responsibility to make sure those integrations actually work reliably at scale.
The fifth principle is planning for the long term from day one. The team structure that works for initial development won’t work for stabilization, which won’t work for production operations. But you need continuity across these phases. This means structuring teams so that the people who build a capability also stabilize it and support it through its first year of production. The complete handoff to a separate operations team is a recipe for disaster.
How We Actually Structure Teams
Let me be specific about what this looks like in practice.
At the program level, you need a small, empowered technical leadership team. This typically includes a chief architect who owns the overall technical vision, a delivery lead who owns execution and velocity, and a head of engineering who owns team quality and capability. These three need to work as a unit, meet daily, and have the authority to make binding decisions without escalating everything to a steering committee.
Below that, you organize around value streams or business capabilities, not technical layers. For a banking transformation, you might have a retail banking team, a corporate banking team, a payments team, and a compliance team. Each team is cross-functional; they have architects, backend developers, frontend developers, testers, and a product manager who understands the business domain. They own their capabilities end to end.
The team size matters. Too small and they can’t deliver enough scope. Too large and coordination overhead kills them. The sweet spot is usually seven to nine people. Large enough to deliver, small enough to stay aligned.
Alongside the capability teams, you need platform and shared services teams. These provide common infrastructure: the API gateway, the identity management layer, the monitoring and observability platform, the CI/CD pipeline. The crucial difference is that platform teams treat capability teams as customers. They’re not command-and-control. They’re enablement. They build tools and services that make capability teams faster.
You also need that integration team we mentioned earlier. This team becomes the experts on your legacy systems, owns the integration patterns, builds reusable connectors, and reviews every integration touchpoint for reliability and performance. They’re often the unsung heroes of enterprise programs.
Testing and quality can’t be a separate phase or a separate team that receives code at the end. Quality is embedded in each capability team, with testers working alongside developers from the beginning. What you do need centrally is a test environment management team and potentially a performance testing team with specialized skills.
For governance and architecture, you create lightweight forums, not heavyweight bureaucracy. A technical design authority that meets weekly to review significant technical decisions. An architecture guild where tech leads share patterns and solve common problems. These are working forums where real decisions get made, not presentation theaters.
Managing Onshore-Offshore Dynamics
Most enterprise programs in India involve some mix of onshore and offshore teams, and this adds another layer of structural complexity.
The mistake is treating location as the primary organizing principle: the India team, the Singapore team, the UK team. This creates geographic silos where teams optimize locally instead of for the program.
Better is to organize around capabilities and then thoughtfully distribute the work. The retail banking team might have developers in India and business analysts onshore. The payments team might be primarily offshore with an onshore tech lead. The integration team might be hybrid because they need regular access to legacy systems.
What matters is communication structure. Teams that need to coordinate frequently should have maximum overlap in working hours. Teams that can work more independently can be distributed. The tech leads need to be in a timezone where they can talk to both the business stakeholders and their development team without being on calls at midnight every day.
You also need to be honest about where decisions get made. If every technical decision requires approval from someone in a different timezone, your velocity will collapse. Distributed teams work when you push decision-making authority down to where the work is happening.
The Vendor Partnership Model
Many enterprise programs involve one or more system integration partners or development vendors. How you structure this partnership shapes everything.
The traditional model is to give the vendor a statement of work and expect them to deliver against it. They staff up, they follow their processes, they give you status reports. This works fine for well-bounded projects but it’s fragile for long-running enterprise programs.
Better is to structure the partnership so vendor teams are integrated into your program structure, not operating separately. If you have a payments capability team, maybe three of those seven people are vendor resources and four are your internal team. They work as one team, not as client and vendor.
This requires a different commercial model not fixed-price per deliverable but a team augmentation or outcome-based model. It requires the vendor to bring not just developers but the right mix of skills. And it requires you to treat vendor team members as true team members, giving them access to systems and information and including them in decisions.
The best partnerships and firms like Ozrit have built their reputation on understanding this are where the vendor brings not just resources but delivery maturity. They’ve seen these problems before. They know the patterns that work in enterprise environments. They can guide team structure, not just fill positions. The relationship feels collaborative rather than transactional.
Planning for Transitions and Continuity
Enterprise programs have phases, and each phase needs somewhat different team structures. But the transitions are where things break.
From design to build, you need to make sure the people who created the architecture are available to guide the developers who implement it. From build to stabilization, you need the developers who built components to be available when those components misbehave in production-like environments. From stabilization to operations, you need enough continuity that knowledge doesn’t evaporate.
This means planning retention. Identify the critical knowledge holders, the people who really understand the domain or the architecture or the integrations and make sure they stay engaged across phases. Sometimes this means adjusting their roles. The tech lead who drove initial development might transition to being the operational architect. The developer who built the integration layer might become the integration support lead.
It also means investing in documentation and knowledge sharing, but not in the bureaucratic way that produces binders nobody reads. Working documentation that teams actually use. Architecture decision records that explain not just what was decided but why. Runbooks that help people troubleshoot problems. Recorded design sessions that new team members can watch to get context.
Keeping Teams Healthy Over the Long Run
Enterprise programs are marathons, and marathon teams need different care than sprint teams.
The first challenge is preventing burnout. Long programs have periods of intense pressure before major releases, during production issues, when deadlines compress. That’s unavoidable. What’s not sustainable is operating at that intensity continuously. Teams need recovery time. This means being realistic about velocity, building a buffer into plans, and having the organizational maturity to say no to scope that would push teams beyond sustainable pace.
The second challenge is keeping people engaged and growing. If someone spends three years working on the same capability in the same way, they stagnate. Good team structures create opportunities for growth: the developer who becomes a tech lead, the tech lead who takes on architecture responsibilities, the specialist who mentors others. People should finish the program having grown, not just survived.
The third challenge is managing team composition changes. People will leave, new people will join. The structure needs to absorb this without collapsing. This means pairing and knowledge sharing is built into how teams work, not something you do only when someone announces they’re leaving. It means onboarding is treated as a serious capability, not an afterthought.
The fourth challenge is maintaining quality and discipline over time. In the beginning, everyone’s enthusiastic about following the architecture, writing tests, doing code reviews. Two years in, when pressure is high and people are tired, these practices erode if they’re not actively maintained. This is where strong technical leadership matters, maintaining standards even when it’s inconvenient.
What Leadership Needs to Do
Team structure doesn’t run itself. It requires active leadership.
From the CIO or CTO level, this means protecting the team structure from constant reorganization pressure. Every few months, someone will propose reshuffling teams or changing the model. Sometimes this is necessary, but often it’s meddling that destroys continuity. Leaders need to understand that team stability is valuable and changing structure has real costs.
It also means investing in the right leadership roles. The technical architect who sets direction. The delivery lead who removes blockers. The head of engineering who builds team capability. These aren’t overhead. These are the roles that make everything else work.
Leaders also need to create the conditions for teams to work effectively. This means fast decision-making processes, not governance structures that require three approvals and a steering committee review to change a technical approach. It means getting teams the access they need to systems, data, and stakeholders. It means running interference when organizational politics threatens to derail technical work.
And it means staying engaged enough to spot when the team structure isn’t working. Are cross-team dependencies creating bottlenecks? Are certain teams consistently struggling while others are thriving? Is knowledge too concentrated in a few people? These are structural problems that need structural solutions, and they won’t fix themselves.
The Measure of Success
You know your team structure is working when teams are shipping features consistently, when technical quality is improving over time rather than degrading, when people want to stay on the program instead of finding excuses to leave, and when new team members can become productive quickly rather than spending months figuring out how things work.
You know it’s working when teams can operate with reasonable autonomy instead of waiting on approvals and coordination. When technical decisions get made at the right level by people with the right context. When problems get solved quickly because the people who need to talk to each other actually talk to each other.
And you know it’s working when the business stakeholders stop worrying about engineering capacity and start focusing on what capabilities they need next, because delivery has become predictable.
This doesn’t mean everything is perfect. Enterprise programs are inherently messy. But with the right team structure, the mess is manageable.
Getting Started
If you’re about to kick off a major enterprise program, spend serious time on team structure before you start writing code. Work through the principles we’ve outlined. Identify the capabilities you need to deliver. Think about ownership and integration. Plan for continuity. Choose your technical leaders carefully.
If you’re in the middle of a program that’s struggling, look at whether team structure is part of the problem. Are teams set up for success or for coordination overhead? Do you have the right leadership in place? Is ownership clear? Sometimes the best intervention is a thoughtful restructuring that gives teams clearer scope and better autonomy.
And whether you’re working with internal teams, vendor partners, or a mix, make sure everyone understands that team structure isn’t just an org chart. It’s how you organize for delivery, for quality, for knowledge sharing, and for long-term sustainability.
Because in enterprise software delivery, technology choices matter, but how you organize the people building that technology matters just as much.