Every enterprise leadership team has experienced the frustration of slow technology delivery. A feature that should take weeks takes months. A simple change requires extensive testing and coordination. Competitors with smaller technology teams somehow ship faster. The business needs agility, but the systems that run the business move at a fraction of the desired pace.
This isn’t a problem of talent or effort. Enterprise technology teams are often staffed with capable engineers working long hours. The problem is structural. Large enterprises have accumulated layers of complexity, dependencies, and constraints that make fast delivery genuinely difficult. Understanding why this happens is the first step toward addressing it.
The Weight of Existing Systems
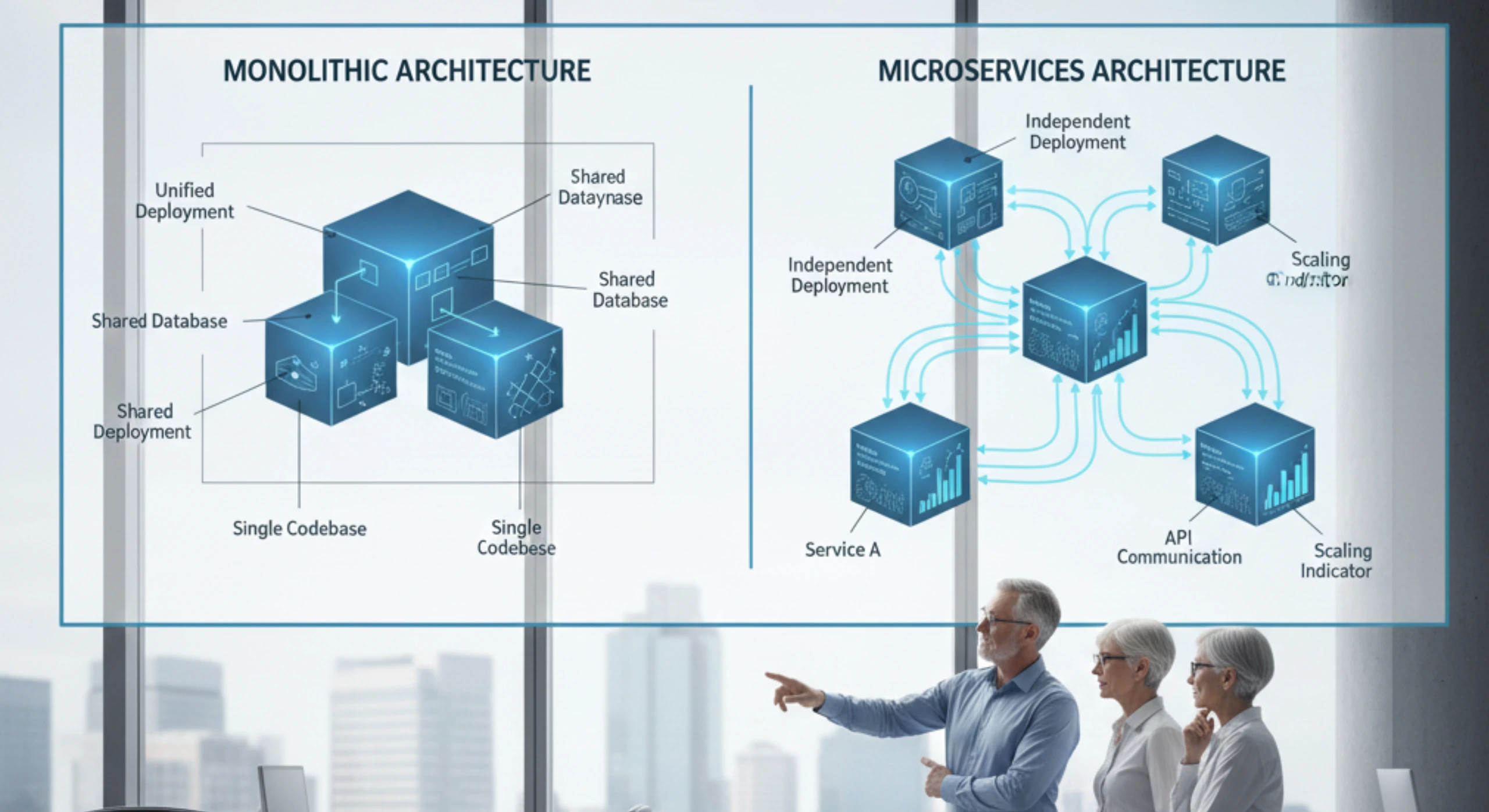
Small companies can move fast because they’re building on clean foundations. They choose modern technology stacks, establish good practices from the start, and don’t have legacy constraints. Every line of code they write is code they understand and control.
Large enterprises operate in a completely different context. They have systems built over decades using technologies that were current at the time but are now outdated. They have databases with schemas designed for business processes that no longer exist. They have integrations built by people who have long since left the company. They have business logic embedded in places nobody remembers.
This accumulated technical infrastructure isn’t optional. These systems run critical business operations. They contain data that can’t be lost. They support processes that generate revenue. You can’t just replace them, and you can’t ignore them when building new capabilities.
Every new feature or system needs to work with this existing infrastructure. A simple customer data update might need to propagate to fifteen different systems. A new checkout flow needs to integrate with a payment system from 2008 and an inventory system from 2012. A mobile app needs data from a mainframe that pre-dates the Internet.
The integration work required to connect new capabilities to existing systems is often more complex than building the new capabilities themselves. And this work is consistently underestimated because it’s invisible until you’re deep into implementation and discover all the edge cases, data quality issues, and system limitations that weren’t obvious upfront.
The Testing Bottleneck
Fast-moving startups can deploy changes continuously because their systems are small enough to test comprehensively, and the blast radius of failures is limited. Enterprise systems require fundamentally different testing approaches because the consequences of failures are severe.
A bug in a consumer app might annoy some users. A bug in an enterprise order processing system might result in thousands of incorrect shipments, lost revenue, and customer trust damage. A performance problem in a banking system might prevent customers from accessing their accounts. The stakes are high, so the testing requirements are proportionally stringent.
The challenge is that comprehensive testing of complex enterprise systems takes time. You need to test the new functionality. You need to test that existing functionality still works. You need to test integrations with other systems. You need to test performance under a realistic load. You need to test edge cases and error conditions. You need to test in environments that mirror production, which means dealing with data privacy requirements and infrastructure costs.
Many enterprises have built extensive automated testing capabilities, but these only partially address the problem. Automated tests can validate known scenarios, but they struggle with the emergent complexity that comes from dozens of systems interacting in production. The tests that catch real problems are often the manual tests performed by people who deeply understand the business processes and can recognize when something doesn’t work correctly.
This testing bottleneck means that even simple changes require days or weeks to validate properly. When you batch multiple changes together to improve efficiency, the testing complexity increases exponentially because now you need to test all the interactions between the changes.
The Coordination Tax
Small teams can move fast because coordination is simple. Everyone sits together, understands the full system, and can make decisions quickly. Large enterprises have technology organizations distributed across locations, time zones, and reporting structures. Getting anything done requires coordination across multiple teams.
Want to update a customer API? You need to coordinate with the team that maintains it, the teams that consume it, the security team that needs to review changes, the architecture team that needs to approve the approach, and the operations team that will deploy it. Each of these teams has its own priorities, schedules, and constraints.
This coordination overhead is substantial and mostly unavoidable. The teams exist for good reasons. The approval processes exist because past incidents demonstrated their necessity. The governance exists because, without it, different parts of the organization would make incompatible decisions.
But the cumulative effect is that simple changes require weeks of meetings, reviews, and approvals before implementation even starts. And if the change touches multiple systems, you multiply this coordination overhead by the number of teams involved.
The enterprises that move fastest aren’t those that eliminate coordination. They’re those that minimize unnecessary coordination through clear ownership boundaries, reduce the approval burden through established patterns and trust, and make essential coordination as efficient as possible.
The Risk Aversion Problem
Enterprise systems support operations that generate billions in revenue. When these systems fail, the business impact is immediate and severe. This creates understandable risk aversion that affects every technology decision.
Teams are reluctant to make changes that might cause outages. Architects design for maximum stability rather than ease of change. Operations teams resist new deployment patterns that they haven’t proven extensively. Everyone remembers the last major incident and wants to avoid being responsible for the next one.
This risk aversion manifests as extensive review processes, conservative technology choices, and reluctance to adopt new approaches even when they would improve delivery speed. The irony is that moving slowly often increases risk rather than reducing it. Changes get batched together into infrequent, large releases that are harder to test and more likely to cause problems. Technical debt accumulates because nobody wants to take the risk of refactoring working code. And the business becomes less adaptable because the systems can’t evolve quickly enough.
Breaking this pattern requires building confidence through proven capability. Small, frequent changes are less risky than large, infrequent ones. Good monitoring and rollback capabilities reduce the consequences of failures. Clear ownership and accountability create the conditions where teams can move faster without unacceptable risk.
The Knowledge Fragmentation Issue
Enterprise systems are too large for any one person to understand completely. Knowledge is fragmented across teams, with each team understanding its part but having limited visibility into how everything fits together.
This fragmentation slows delivery in subtle but significant ways. When you start a project, you need to find the people who understand the relevant systems. When you encounter an unexpected behavior, you need to track down someone who can explain it. When you make a change, you need to identify everyone who might be affected. Each of these knowledge-finding activities takes time.
Documentation helps, but is never complete or current enough. The real knowledge lives in people’s heads, accumulated through years of working with specific systems. When those people leave or move to different roles, that knowledge leaves with them unless it’s been successfully transferred to others.
Many enterprises have attempted to solve this through better documentation, knowledge management systems, or architectural diagrams. These help at the margins but don’t fundamentally address the problem that complex systems contain more knowledge than can be easily captured and maintained in documentation.
The better solution is to reduce the knowledge required to work productively. This means building systems with clearer boundaries, better abstractions, and more predictable behaviors. It means standardizing patterns so that knowledge transfers across different parts of the system. And it means investing in onboarding and knowledge transfer as core capabilities rather than afterthoughts.
The Technical Debt Trap
Technical debt is the accumulated cost of past shortcuts, changing requirements, and systems that have outlived their original design. Every enterprise has substantial technical debt, and it directly affects delivery speed.
Code that was written quickly and never refactored becomes difficult to modify safely. Architectures that were appropriate for earlier requirements become constraints on new capabilities. Dependencies on outdated frameworks or libraries require workarounds and compatibility layers. Each of these technical debt items adds friction to every change that touches the affected systems.
The rational response is to pay down technical debt through systematic refactoring and modernization. But this work competes with feature development for resources, and features usually win because they have clear business value, while technical debt reduction seems like overhead.
Over time, technical debt compounds. The systems that are hardest to change are the ones most in need of change. Teams take increasingly elaborate workarounds to avoid modifying problematic code. Development velocity decreases year over year despite constant investment. Eventually, you reach a point where the only solution is a major rewrite or replacement, which is expensive and risky.
The enterprises that maintain delivery speed are those that allocate consistent capacity to technical debt reduction and treat it as essential maintenance rather than optional work. They recognize that paying down debt incrementally is far cheaper than letting it accumulate until a crisis forces expensive remediation.
How Ozrit Helps Enterprises Move Faster
At Ozrit, we work with enterprises that need to accelerate delivery while managing the inherent complexity of large-scale systems. Our approach is based on understanding that speed comes from addressing the structural issues, not just adding more engineering capacity.
We start with an assessment that identifies the specific factors slowing delivery in your environment. This goes beyond cataloging technical debt. We examine testing processes, coordination overhead, knowledge distribution, risk management practices, and organizational structure. This assessment typically takes three to four weeks and involves our senior team working with people across your technology organization.
The goal is to understand not just what’s slow, but why it’s slow and what would actually improve delivery speed. Sometimes the bottleneck is technical. Often it’s organizational or process-related. And frequently it’s a combination where technical and organizational factors reinforce each other.
Based on this assessment, we develop a delivery acceleration program that addresses the highest-impact constraints first. This might include reducing technical debt in critical systems, improving testing automation, establishing clearer ownership boundaries, or building shared capabilities that reduce coordination overhead. We structure the work in phases that deliver measurable improvements in delivery speed within three to four months.
Each program has a dedicated senior delivery lead from our team who owns the execution and outcomes. This person coordinates across workstreams, manages dependencies, and ensures consistent progress. They’re experienced engineers who have worked in large enterprise environments and understand both the technical and organizational challenges that affect delivery speed.
Our onboarding process gets teams productive quickly despite the complexity of enterprise environments. We assign engineers from our team of 250+ developers and specialists who have worked in similar environments and understand the patterns that make enterprises slow. They spend their first two to three weeks learning your systems, processes, and organizational context. By week four, they’re contributing to improvements.
We handle the difficult technical work that’s often needed to accelerate delivery. Refactoring complex legacy code. Improving test coverage and automation. Building deployment pipelines that enable faster, safer releases. Modernizing architectures to reduce coupling and dependencies. Our engineers have done this work at scale and know how to make meaningful progress without disrupting ongoing operations.
Because we operate across time zones with 24/7 coverage, we can maintain continuous momentum on acceleration programs. We can also respond quickly when issues arise, which builds the confidence needed to move faster. Teams are more willing to deploy changes frequently when they know experienced engineers are available immediately if something goes wrong.
The Path to Sustainable Speed
Moving fast in enterprise environments isn’t about cutting corners or accepting more risk. It’s about systematically addressing the structural factors that create drag on delivery.
This requires investment in technical capabilities like automated testing, modern deployment practices, and clean architectures. It requires organizational changes like clearer ownership, streamlined approvals, and better coordination mechanisms. And it requires cultural shifts around acceptable risk, the value of technical quality, and the importance of continuous improvement.
The enterprises that succeed at this see compounding benefits over time. As technical debt decreases, changes become easier and safer. As testing improves, release cycles can shorten. As ownership becomes clearer, coordination overhead decreases. Each improvement enables the next, and delivery speed increases progressively.
The question isn’t whether enterprise systems can move fast. It’s whether leadership is willing to invest in the capabilities and changes required to make fast delivery sustainable rather than just demanding speed and hoping the constraints will somehow resolve themselves.